
Building from scratch

Have you ever wondered what architectural choices you would make if you were to build a Core Banking Solution from scratch?
Neill Elliott, Chief Product Officer at SaaScada, has been pondering this topic and has shared some of his thoughts in this article.
So, you have decided you want to build a Core Banking Solution from Scratch. You have been out to the market and feel that all vendors are peddling the same legacy solution but with different wrappers and pricing models and none of them deliver what you feel you need to help you deliver your new digital banking offering to your customers.
Sounds great but where do you start? The products that are available on the market have been around for a number of years and benefit from that experience in the features they offer so developing a new one is going to be quite challenging but those products also suffer from the limitation of being designed and built long before digital banking became a “thing” so starting from scratch makes a lot of sense, if you have the appetite.
So where does one start?
As with any Enterprise solution, our design needs to adhere to certain principles and for the purposes of this piece, these are the ones I will be following:
- MACH (Microservice based, API First, Cloud Native and Headless)
- Resilient, Scalable, Performant and Highly Available
- Process in Real Time
- Event Driven (use events to trigger actions between services)
- Data Centric (enable solution to form part an Enterprise Data Driven Architecture).
All these principles are worthy of a separate article, and I am sure there are others that I have not listed which are equally important (there are a lot of Architectural Design Patterns to choose from). However, I am only going to focus on the last two, Event Driven and Data Centric as they will dictate my database choices (although the choice will also need to fit with the second point)
All core banking solutions centre around the Ledgers as this is where the “value” is stored. Layered on top of this are Product Capabilities that turn the Ledgers into Accounts (Savings, Loans, Current Accounts), Payment Services to enable Deposits and Withdrawals and other services to support the Assisted and Self Service Channels. We will therefore start with the ledger design. Should be simple enough.
Our Financial Institution will be offering services centred around the end Customer and providing the best experience through the channels we will offer. Customer centricity and personalisation requires easy access to data that resides in the numerous applications that our platform will comprise so it can be processed by campaign engines, explainable AI models (XAI) and other Data Analytical tooling to generate outcomes to enhance the experience. The data needs to be accessible in real time, on demand or via scheduled extracts to satisfy all the different use cases.
On demand access to real time data will put additional query-based load on our platform over and above the normal load for servicing accounts and customers. This load is typically difficult to scale and model so we will need to consider this in our design, in order to adhere to our design principles.
Figure 1 – Traditional Database Model
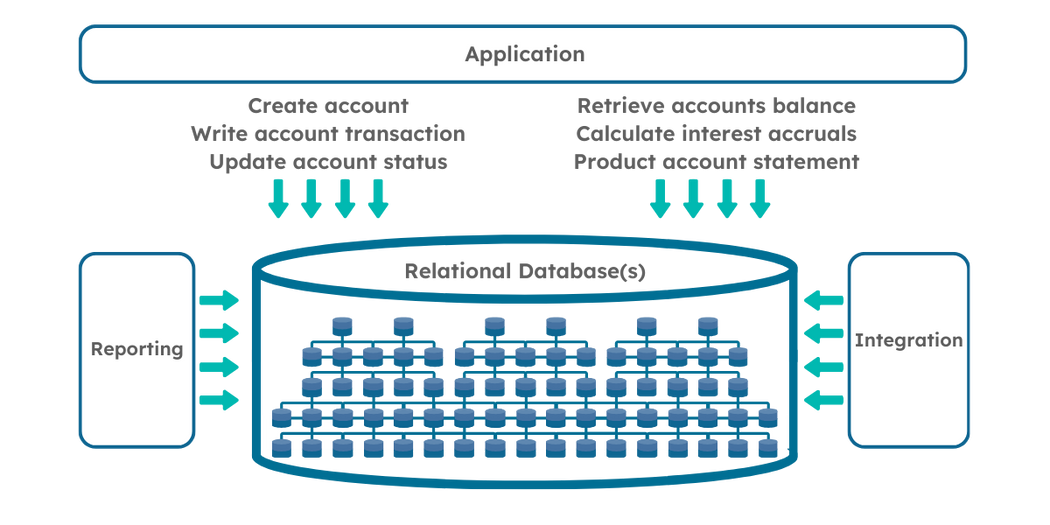
Fortunately, this is exactly the problem that the Command Query Responsibility Separation (CQRS) design pattern seeks to help resolve. The pattern allows the query load to be separated from the command load so that each can be scaled independently so ideal for our platform.
Command and Query Responsibility Segregation or CQRS, is an Architectural design pattern that separates read and update operations for a data store. Implementing CQRS in an application can maximise its flexibility, performance, scalability, and security, allowing the system to better evolve over time.
Traditionally, core banking solutions were built around one single relational data model that is used for all read and write (CRUD) operations. It was simple to implement and was historically the way all mainframe systems were developed as it works well for basic CRUD operations. Over time though, core banking solutions have been become more and more complex due to banking moving from being purely branch based to multi-channel, and this single database approach has now become unwieldy.
For example, on the query side, the increasing demand for data means that an application may perform many different queries with different data and filtering demands thus putting excessive load on the database engine. In addition to supporting this, it may be necessary to implement complex validation and business logic to support various Command use cases and as a result, the database model becomes overly complex as it tries to do too much.
CQRS recommends that reads and writes are isolated into separate database operations, using task-based commands to update data, and data centric queries to read data, each of which can be optimised to support the workload as well as being independently scalable as shown below.
Figure 2 – CQRS Design Pattern
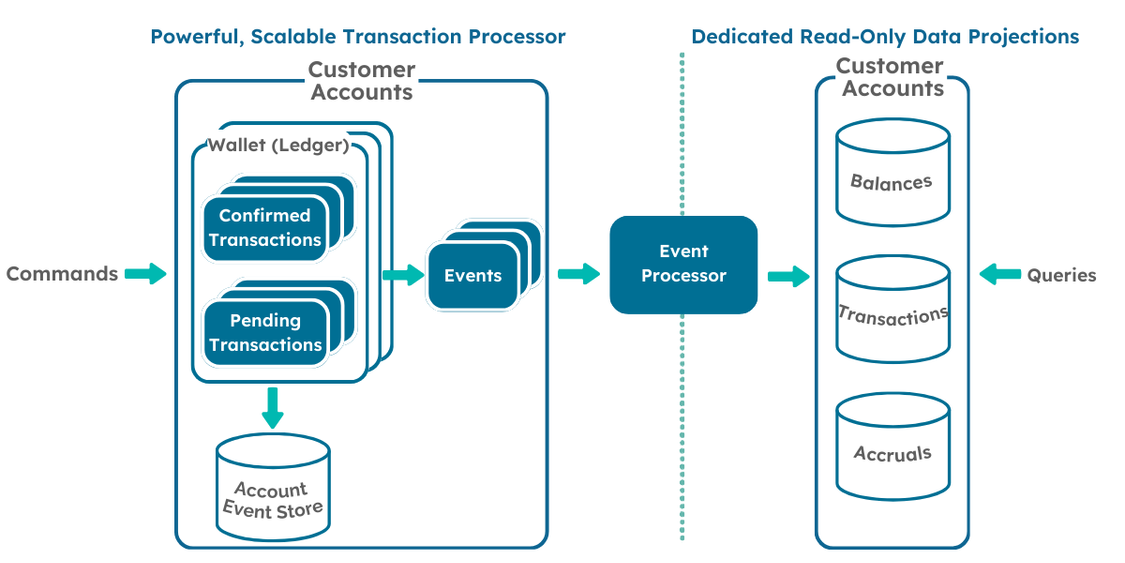
Implementing this architecture should address some of the scaling and performant elements of our principles but will also go some way to addressing the principle of being Event Driven. This is because it will be necessary to use event streaming between the command and query services in order to make this design work.
We will be offering, our customers, services centred around them and therefore our platform not only needs to publish all data that it holds but it also needs to avoid any data loss that may result in posting transactions to a fixed schema. Historically, enterprise applications were built around a single relational database, and we have already discussed why that is no longer a viable option with the differing demands between Commands and Queries; something we are looking to solve by implementing CQRS. However, the other limitation of using a relational database is the fact that all data that we receive through Commands needs to be “shoe-horned” into a fixed canonical data structure which will either result in data loss or an unwieldly and inflexible database structure that caters for all inbound data (and store a large amount of unnecessary null data for columns that relate to specific commands).
To address this limitation, let’s look to the flexibility of NoSQL.
NoSQL stands for Not only SQL. It is a type of database that uses non-relational data structures, such as documents, graph databases, and key-value stores to store and retrieve data. The primary benefit of this is that it provides developers with the ability to store and access data quickly and easily, without the overhead of a traditional relational database. It also has other advantages such as:
Flexibility – NoSQL databases have flexible schemas that allow for faster development. They can store data in ways that are easier to understand and closer to how applications use it.
Scalability – NoSQL databases can scale out horizontally by using distributed hardware clusters, rather than scaling up by adding more servers. This makes it easy to add or remove cloud resources as needed.
High performance – NoSQL databases are optimized for specific data models and access patterns. They can deliver data quickly and reliably, even when data volumes or traffic increase.
Durability – NoSQL databases ensure that transactions are permanently saved, even after a database crash.
Ease of use – NoSQL cloud databases are often easy to deploy and manage, with much of their complexity hidden from end users.
Security – NoSQL cloud databases are typically backed up, replicated, and secured against intrusion.
The decision of which type of database to use for our platform (SQL or NoSQL) depends on the needs and requirements of our use cases as ultimately, there is no one-size-fits-all solution. It all depends on what is needed from our database and which type of system can provide that in the most efficient manner. In order to determine which best suits the data storage needs for our CQRS based core banking platform, let’s dig a little deeper into the key differences between them.
At the most basic level, the biggest difference between the two technologies is that SQL databases are relational, NoSQL databases are non-relational. Relational databases store data in rows and tables and connect information between tables using Primary and Foreign keys (unique identifiers that the database assigns to rows of data in tables). Non-relational or NoSQL databases store data just like relational databases but they don’t contain any rows, tables, or keys. They utilise a storage model based on the type of data they store.
SQL databases use structured query language and have a pre-defined schema for defining and manipulating data. SQL is one of the most versatile and widely used query languages available, making it a safe choice for many use cases. It’s perfect for complex queries but can also be too restrictive. You must use predefined schemas to determine your data structure before you can work with it. All your data must follow the same structure, and this process requires significant upfront preparation. Whenever the data structure needs to change, it can be disruptive to the whole system.
NoSQL databases have dynamic schemas for unstructured data and store data in many ways. You can use column-oriented, document-oriented, graph-based, or KeyValue stores for your data. This flexibility means documents can be created without firstly having to define their structure. Each can have its own unique structure and will support the addition of new fields when required.
Another key difference between them is scaling. SQL databases are vertically scalable in most situations, meaning you can only increase the load on a single server by adding more CPU, RAM, or SSD capacity. NoSQL databases are horizontally scalable, so you can handle higher traffic via a process called sharding, which adds more servers to your NoSQL database. Horizontal scaling has a greater overall capacity than vertical scaling, making NoSQL databases the preferred choice for large and frequently changing data sets.
SQL databases are table-based, where each field in a data record has the same name as a table column. NoSQL databases are document, key-value, graph, or wide-column stores. These flexible data models make NoSQL databases easier for some developers to use.
Based upon this, SQL is going to be the best database for the query side of our platform as it is better for multi-row transactions; NoSQL is better for the unstructured Event data we will store in our Event Store thus avoiding data truncation and adding the flexibility to store more data as the inbound data changes, thus allowing us to store the entire ISO8583 or ISO20022 message we received.
However, using NoSQL for the command side of our platform will not resolve the data loss issue on its own as we would still need to track running totals (such as Balance, accrued fees etc), which would still require the need for relational data entities, just stored in a NoSQL database. In order to minimise data loss, we need to consider basing our Ledger design on Event Sourcing.
Event Sourcing is an Architectural Design pattern which offers an alternative approach of storing the changes to the ledger. Rather than storing the current state (Balance, Transactions etc) in an account master and Transaction detail tables, as has traditionally been done, Event Sourcing states that all changes of state are stored as immutable events against the account. In this alternative model, querying the balance would mean processing the historic events and evaluating them in chronological order on demand, thus avoiding any synchronisation issues in the relational model. The following diagram shows how these events will be stored against our Ledgers.
Figure 3 – Event Sourcing Design Pattern
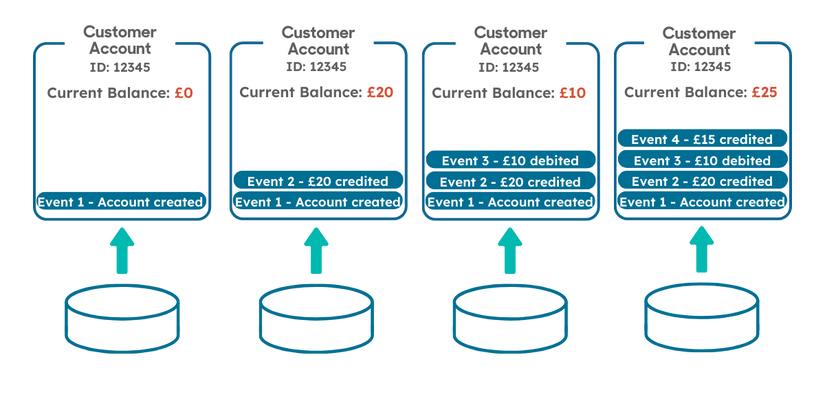
This has appeal from a financial perspective. Once committed, ledger entries should never be changed and what better way to determine the current balance than to reconcile all previous transactions.
Thus far, our design is satisfying the need for Real Time processing, whilst being Event Driven, Resilience, Scalable and Performant. It has done this by using a combination of the CQRS and Event Sourcing patterns along with a mixture of SQL and NoSQL databases but what about the solution being data centric. Data Centricity as a design principle is basically ensuring that Data is at the core of the design and influencing how components interact, data is processed and how insights are extracted. We have certainly been focused on how data is processed with the use of CQRS to separate the Reads and Writes and NoSQL to minimise data loss in the processing of commands, but we have not discussed how all that data is made available in real time so that other applications within the Enterprise can derive the necessary insights required to provide a Customer Centric service.
Event Sourcing has defined our approach to storing account data as events and we are publishing those events to the solution’s query services (as per CQRS) so it would make sense to make those events available to bespoke data projections for specific data insights as well as publish them to external services via Webhooks. This will ensure that the Financial Institutes’ Enterprise Architect has options as to how best to incorporate our solution with his wider Data Driven Architectural Design. The use of NoSQL will minimise data loss so the solution will be able to publish, all of the data we received on the command as well as any additional data that was added while the command was processed.
The figure below shows how the data will flow from Command to Webhook. Figure 4 – Schematic of the flow of data through our design
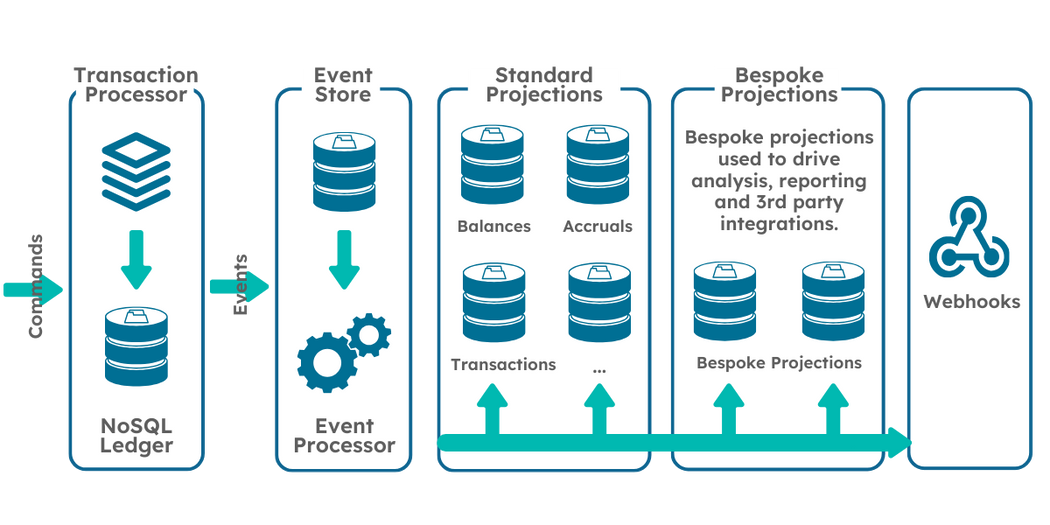
So, in summary, our CQRS based platform will have separate services and databases for commands and queries that are independently scalable. The command side will include a Transaction processor service that will process commands against the ledgers, querying the Event Store on demand for validation (Balances, Accrued Interest, Fees etc) and writing state change events to the event store which will be a NoSQL database to avoid data truncation. These Events will be published for other subscribers (both internal and external). Query services will be created to derive balances, transactions and other financial information by processing these events either on demand or by consuming the events as they happen to populate a relational database. Webhooks will be created for these events which External systems can elect to subscribe to (via endpoint configuration).
If you would like to to know more about how SaaScada’s approach to core banking architecture powers innovation at pace, contact us or email [email protected]


